
这是三部分系列中的第三篇文章,它将提供对Go中垃圾收集器背后的机制和语义的理解。这篇文章重点介绍GC如何自我调整。
三部分系列的索引:
1)Go中的垃圾收集:第一部分 - 语义
2)Go中的垃圾收集:第二部分 - GC跟踪
3)Go中的垃圾收集:第三部分 - GC步伐
介绍
在第二篇文章中,我向你展示了垃圾收集器的行为以及如何使用工具查看收集器对正在运行的应用程序造成的延迟。我带你了解了一个真实的Web应用程序,并向你展示了如何生成GC跟踪和应用程序配置文件。然后,我向你展示了如何解释这些工具的输出,以便你可以找到提高应用程序性能的方法。
该帖子的最终结论与第一篇相同:如果减少堆上的压力,你将减少延迟成本,从而提高应用程序的性能。与垃圾收集器同情的最佳策略是减少每个工作的分配数量或数量。在这篇文章中,我将展示调步算法如何能够识别给定工作负载随时间的最佳速度。
并发示例代码
我将使用此链接中的代码。
https://github.com/ardanlabs/gotraining/tree/master/topics/go/profiling/trace
该程序确定在RSS新闻订阅源文档集合中可以找到特定主题的频率。跟踪程序包含不同版本的查找算法,以测试不同的并发模式。我将集中在freq,freqConcurrent和freqNumCPU的算法版本。
注意:我在Macbook Pro上运行代码,使用带有12个硬件线程的Intel i9处理器,使用go1.12.7。你将在不同的体系结构,操作系统和Go版本上看到不同的结果。该职位的核心成果应保持不变。
我先从freq版本开始。它表示程序的非并发顺序版本。这将为后续的并发版本提供基线。
清单1
1 | 01 func freq(topic string, docs []string) int { |
清单1显示了该freq函数。此顺序版本的范围超过文件名集合,并执行四个操作:打开,读取,解码和搜索。它为每个文件执行此操作,一次一个。
当我freq在我的机器上运行此版本时,我得到以下结果。
清单2
1 | $ time ./trace |
你可以通过输出时间看到,程序需要大约2.5秒来处理4000个文件。很高兴看到在垃圾收集中花费了多少时间。你可以通过查看程序的痕迹来做到这一点。由于这是一个启动和完成的程序,因此你可以使用跟踪包生成跟踪。
清单3
1 | 03 import "runtime/trace" |
清单3显示了从程序生成跟踪所需的代码。trace从runtime标准库中的文件夹导入包后,调用trace.Start和trace.Stop。将跟踪输出os.Stdout定向为简化代码。
使用此代码,现在你可以重新生成并再次运行该程序。不要忘记重定向stdout到文件。
清单4
1 | $ go build |
运行时添加了100多毫秒,但这是预期的。跟踪捕获每个函数调用,进出,直到微秒。重要的是,现在有一个名为t.out包含跟踪数据的文件。
要查看跟踪,需要通过跟踪工具运行跟踪数据。
清单5
1 | $ go tool trace t.out |
运行该命令会使用以下屏幕启动Chrome浏览器。
注意:跟踪工具使用Chrome浏览器内置的工具。此工具仅适用于Chrome。
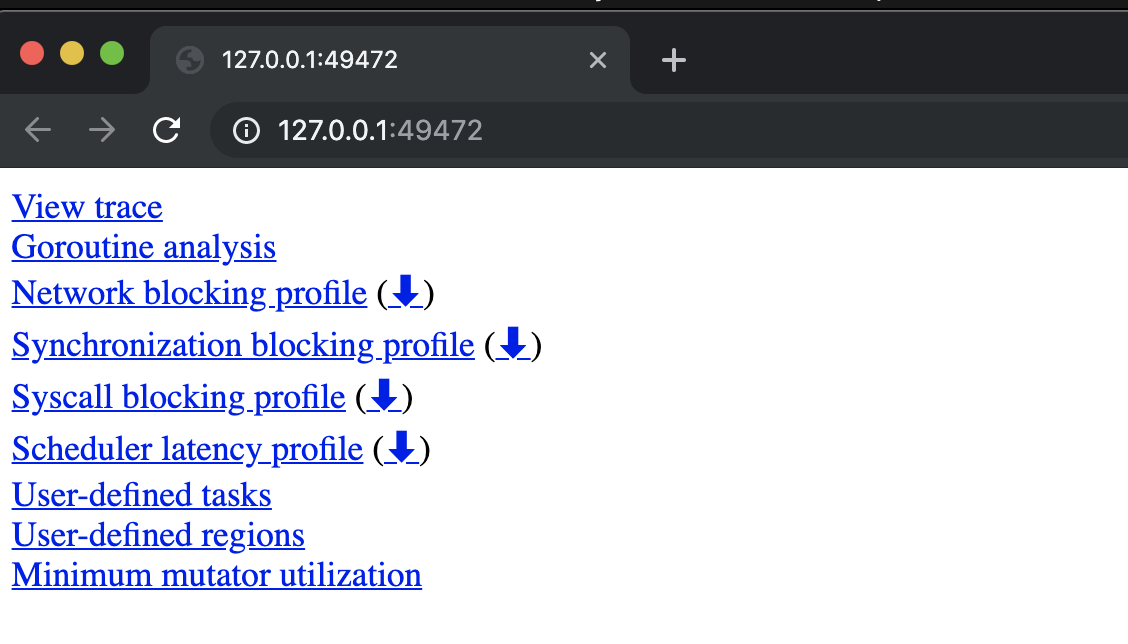
图1
图1显示了跟踪工具启动时显示的9个链接。现在重要的链接是第一个链接View trace。选择该链接后,你将看到类似于以下内容的内容。
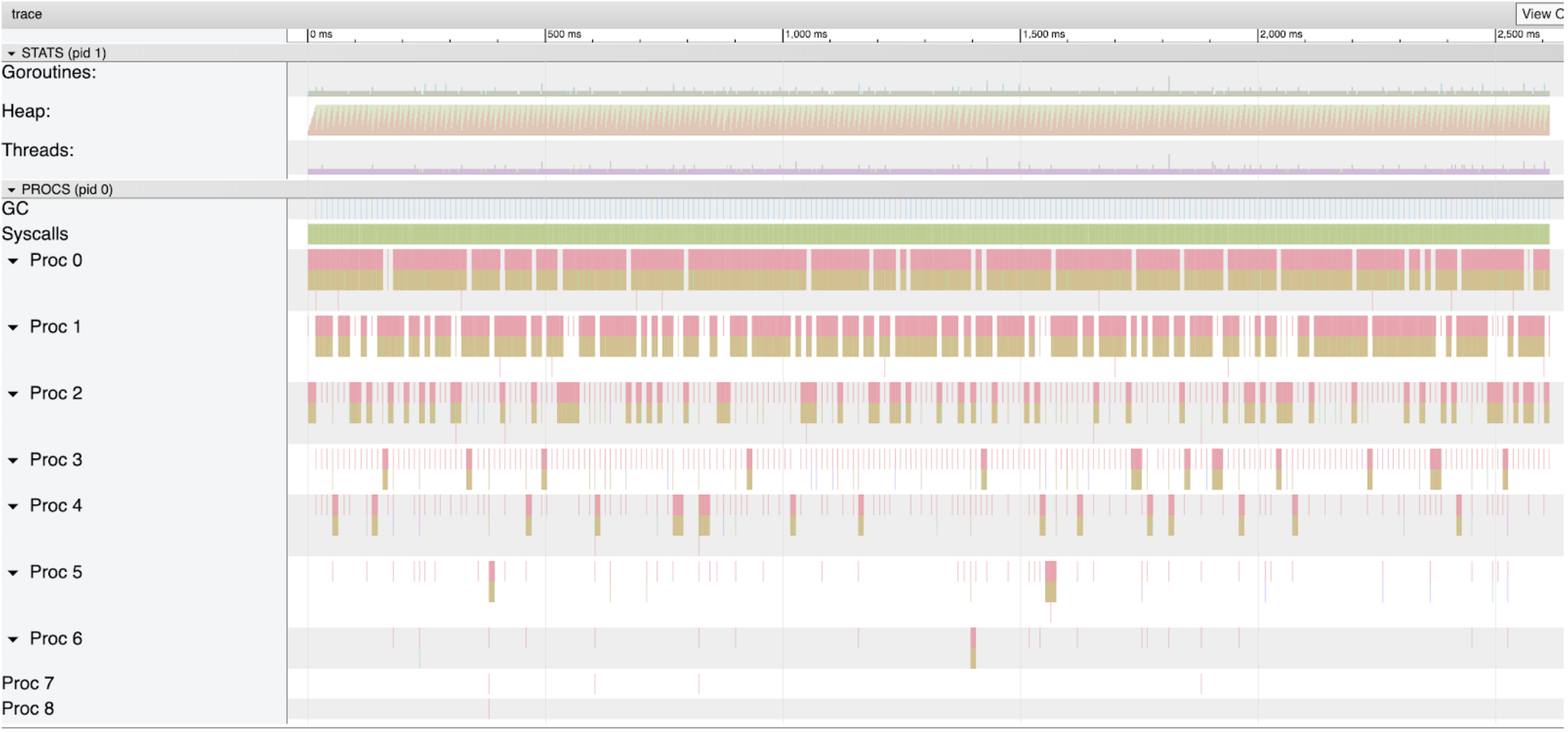
图2
图2显示了在我的机器上运行程序的完整跟踪窗口。对于这篇文章,我将重点介绍与垃圾收集器相关的部分。这是第二部分标记Heap,第四部分标记GC。
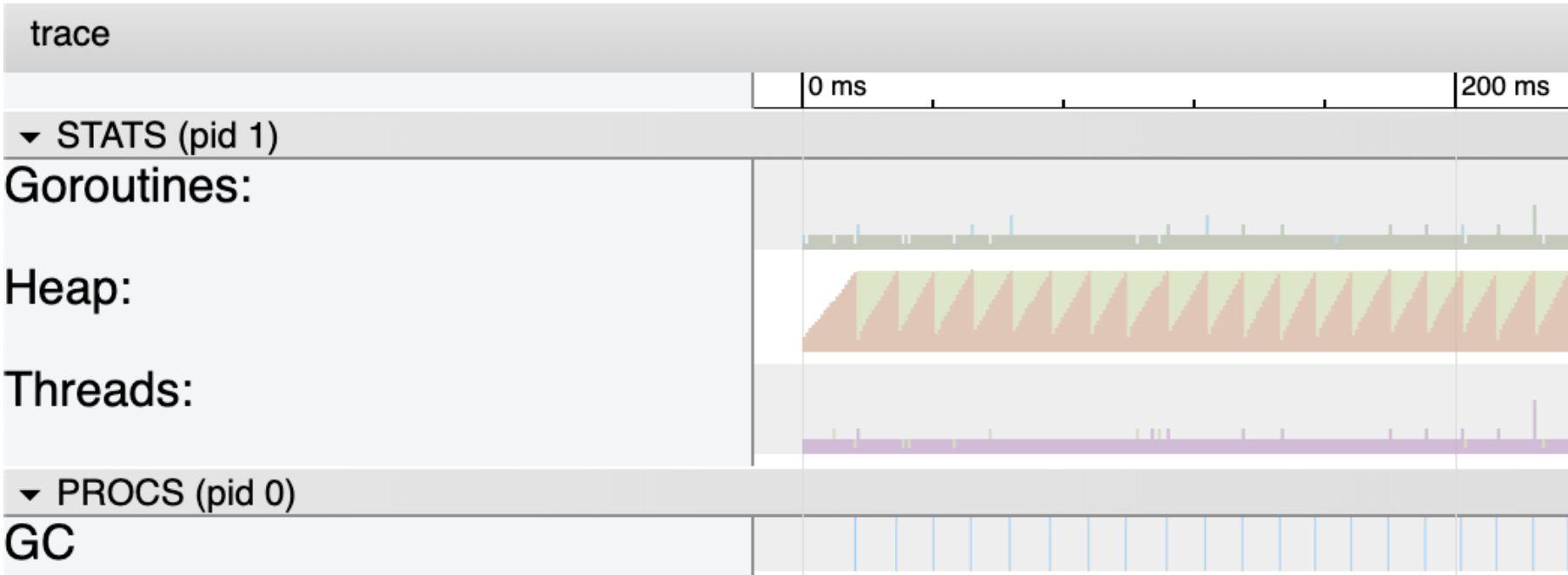
图3
图3更详细地展示了跟踪的前200毫秒。将注意力集中在Heap(绿色和橙色区域)和GC(底部的蓝线)上。该Heap部分向你展示了两件事。橙色区域是堆上任何给定微秒的当前正在使用的空间。绿色是堆上将触发下一个集合的正在使用的空间量。这就是为什么每当橙色区域到达绿色区域的顶部时,就会发生垃圾收集。蓝线代表垃圾收集。
在此版本的程序中,堆上使用的内存在整个程序运行时保持在~4mcg。要查看有关发生的所有单个垃圾收集的统计信息,请使用选择工具并在所有蓝线周围绘制一个框。

图4
图4显示了如何使用箭头工具在蓝线周围绘制蓝框。你想在每一行画出框。框内的数字表示从图表中选择的项目消耗的时间量。在这种情况下,选择接近316毫秒(ms,μs,ns)来生成此图像。选择所有蓝线后,将提供以下统计数据。

图5
图5显示图中的所有蓝线都在15.911毫秒标记到2.596秒标记之间。共有232个垃圾收集,代表64.524毫秒的时间,平均收集时间为287.121微秒。知道程序运行需要2.626秒,这意味着垃圾收集只占总运行时间的2%。基本上垃圾收集器是运行该程序的一个微不足道的成本。
有了可以使用的基线,可以使用并发算法执行相同的工作,以期加快程序的速度。
清单6
1 | 01 func freqConcurrent(topic string, docs []string) int { |
清单6显示了一个可能的并发版本freq。此版本的核心设计模式是使用扇出模式。对于docs集合中列出的每个文件,都会创建一个Goroutine来处理该文件。如果要处理4000个文档,则使用4000个Goroutine。这种算法的优点是它是利用并发性的最简单方法。每个Goroutine处理1个且只有1个文件。等待处理每个文档的编排可以使用a来执行WaitGroup,并且原子指令可以使计数器保持同步。
该算法的缺点在于它不能很好地适应文档或核心的数量。所有的Goroutine都会有时间在程序开始时很早就运行,这意味着很快就会消耗大量的内存。found在第12行添加变量也存在缓存一致性问题。由于每个核心共享该变量的相同缓存行,这将导致内存抖动。随着文件或核心数量的增加,这会变得更糟。
使用此代码,现在你可以重新生成并再次运行该程序。
清单7
1 | $ go build |
你可以通过清单7中的输出看到,程序现在需要951毫秒来处理相同的4000个文件。这是性能提升约64%。看看跟踪。
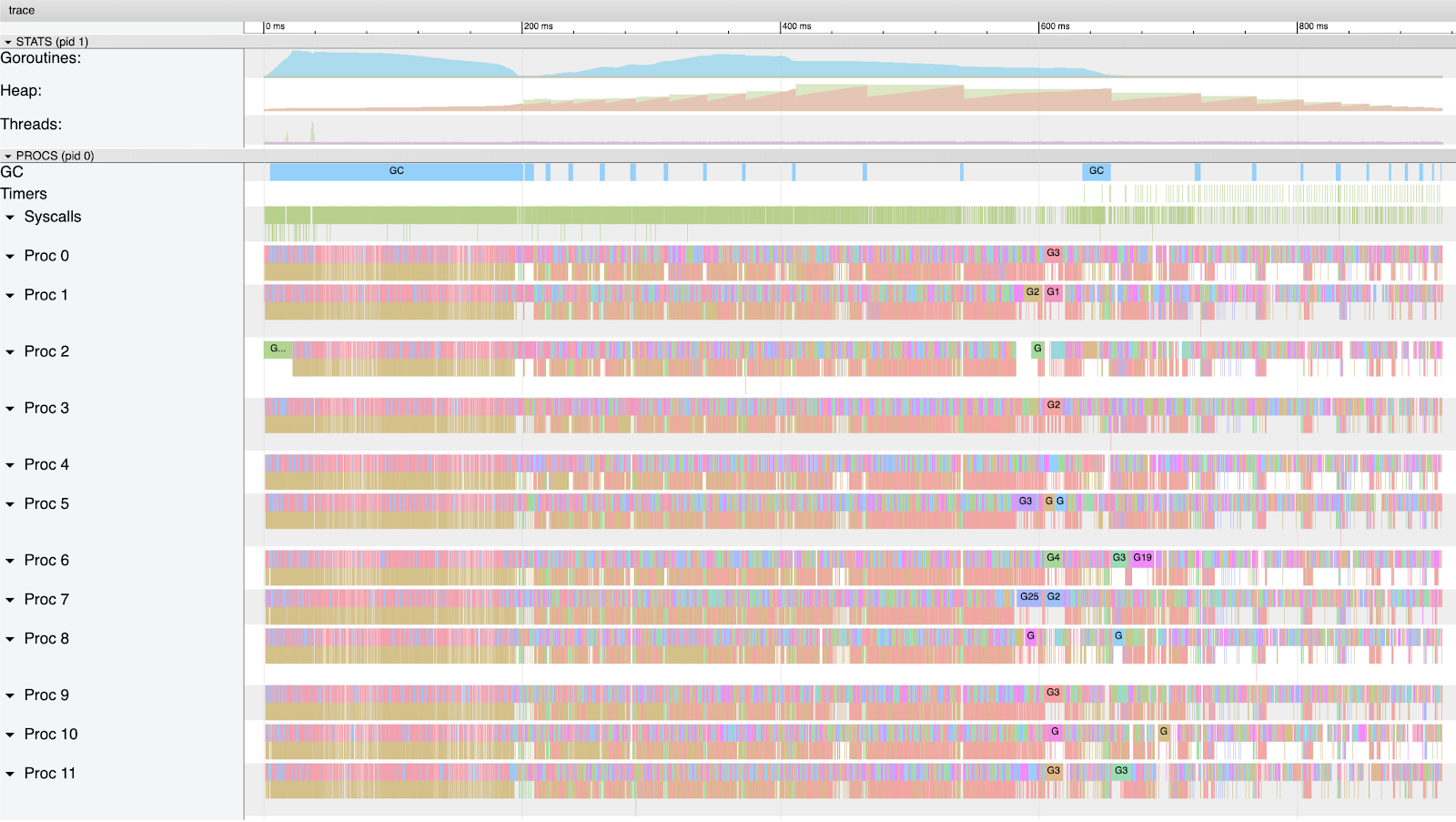
图6
图6显示了此版本程序正在使用的计算机上的CPU容量。图表的开头有很多密度。这是因为当所有Goroutine都被创建时,它们会运行并开始尝试在堆中分配内存。一旦分配了前4兆内存,这很快就会启动GC。在此GC期间,每个Goroutine都有时间运行,并且当它们在堆上请求内存时,大多数都会进入等待状态。到GC完成时,至少有9个Goroutine继续运行并将堆增加到~26 meg。

图7
图7显示了第一个GC的大部分时间内大量的Goroutine处于Runnable和Running状态以及如何快速重新启动。请注意,堆配置文件看起来不规则,并且集合不像以前那样处于任何常规节奏上。如果仔细观察,第二个GC几乎会在第一个GC后立即开始。
如果你选择此图表中的所有集合,你将看到以下内容。

图8
图8显示图中的所有蓝线都在4.828毫秒标记到906.939毫秒标记之间。共有23个垃圾收集,代表284.447毫秒的时间,平均收集时间为12.367毫秒。知道该程序运行需要951毫秒,这意味着垃圾收集占总运行时间的约34%。
这与顺序版本在性能和GC时间方面存在显着差异。但是,按照它的方式并行运行更多的Goroutine,可以让工作完成~64%的速度。成本需要更多的资源在机器上。不幸的是,在堆上一次正在使用大约200兆的内存。
使用并发基线,下一个并发算法会尝试使用资源更高效。
清单8
1 | 01 func freqNumCPU(topic string, docs []string) int { |
清单8显示了freqNumCPU该程序的版本。此版本的核心设计模式是使用池模式。基于处理所有文件的逻辑处理器数量的Goroutine池。如果有12个逻辑处理器可供使用,则使用12个Goroutine。该算法的优点在于它始终保持程序的资源使用一致。由于使用了固定数量的Goroutine,因此只需要在任何给定时间需要12个Goroutine的存储器。这也解决了缓存一致性问题与内存抖动。这是因为对第14行的原子指令的调用只需要发生很小的固定次数。
该算法的缺点是更复杂。它增加了一个通道的使用来为Goroutines池提供所有工作。在使用任何时间池时,识别池的“正确”数量的Goroutine是复杂的。作为一般规则,我为每个逻辑处理器启用池1一个Goroutine。然后执行负载测试或使用生产指标,可以计算池的最终值。
使用此代码,现在你可以重新生成并再次运行该程序。
清单9
1 | $ go build |
你可以通过清单9中的输出看到,该程序现在需要754毫秒来处理相同的4000个文件。该程序的速度提高约200毫秒,这对于这个小负载来说非常重要。看看跟踪。

图9
图9显示了此版本程序如何使用我机器上的所有CPU容量。如果你密切关注,那么该计划将再次具有一致的干扰。与顺序版非常相似。
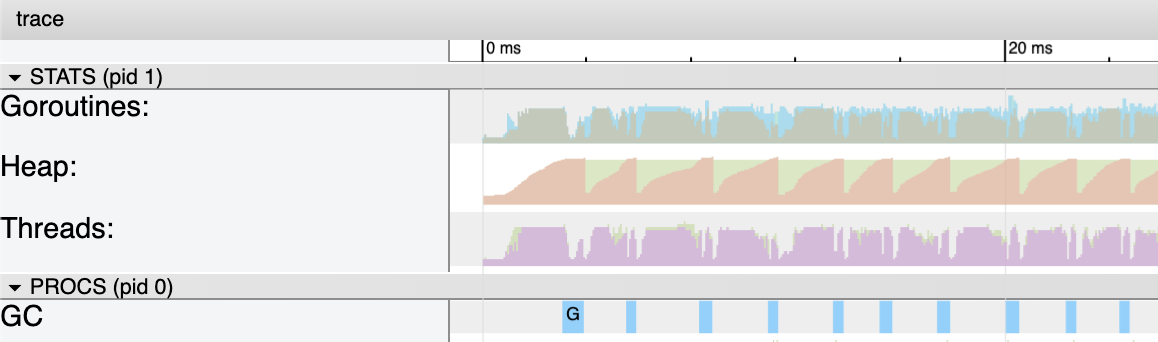
图10
图10显示了如何仔细查看程序前20毫秒的核心指标。这些集合肯定比顺序版本更长,但有12个Goroutines正在运行。堆上使用的内存在整个程序运行时保持在~4mcg。同样,与程序的顺序版本相同。
如果你选择此图表中的所有集合,你将看到以下内容。

图11
图11显示图中的所有蓝线都在3.055毫秒标记到719.928毫秒标记之间。共有467个垃圾收集,代表177.709毫秒的时间,平均收集时间为380.535微秒。知道该程序运行需要754毫秒,这意味着垃圾收集占总运行时间的约25%。比其他并发版本提高9%。
此版本的并发算法似乎可以使用更多文件和内核进行更好的扩展。我认为复杂性成本是值得的。可以通过将列表切换成每个Goroutine的工作桶来替换该通道。这肯定会增加更多的复杂性,尽管它可以减少通道产生的一些延迟成本。在更多文件和核心上,这可能是重要的,但需要测量复杂性成本。这是你可以自己尝试的东西。
结论
我喜欢比较算法的三个版本是GC如何处理每种情况。处理文件所需的内存总量不会随任何版本而变化。程序如何分配有什么变化。
当只有一个Goroutine时,只需要一个4兆的基础堆。当程序立即将所有工作都放在运行时时,GC采用了让堆增长的方法,减少了集合的数量,但运行了更长的集合。当程序控制在任何给定时间处理的文件数时,GC采取了再次保持堆小的方法,增加了集合的数量但运行较小的集合。GC采用的每种方法基本上允许程序运行,GC可能对程序产生最小的影响。
1 | | Algorithm | Program | GC Time | % Of GC | # of GC’s | Avg GC | Max Heap | |
该freqNumCPU版本还有其他功能,比如更好地处理缓存一致性,这是有帮助的。但是,每个程序的GC时间总量的差异非常接近,约为284.4毫秒vs 177.7毫秒。有些日子在我的机器上运行这个程序,这些数字更接近。使用版本1.13.beta1运行一些实验,我看到两个算法在相同的时间运行。潜在地暗示它们可能会有一些改进,使GC能够更好地预测如何运行。
所有这些让我有信心在运行时抛出大量工作。这是一个使用50k Goroutines的Web服务,它本质上是一个类似于第一个并发算法的扇出模式。GC将研究工作量并找到服务的最佳速度以避开它。至少对我来说,不必考虑任何这个是值得入场的代价。

