由于 API 接口无法控制调用方的行为,因此当遇到瞬时请求量激增时,会导致接口占用过多服务器资源,使得其他请求响应速度降低或是超时,更有甚者可能导致服务器宕机。
限流指对应用服务的请求进行限制,例如某一接口的请求限制为 100 个每秒, 对超过限制的请求则进行快速失败或丢弃。
限流可以应对:
热点业务带来的突发请求;
调用方 bug 导致的突发请求;
恶意攻击请求。
因此,对于公开的接口最好采取限流措施。
一、限流的算法 实现限流有很多办法,在程序中时通常是根据每秒处理的事务数 (Transactionpersecond) 来衡量接口的流量。
本文介绍几种最常用的限流算法:
固定窗口计数器;
滑动窗口计数器;
漏桶;
令牌桶。
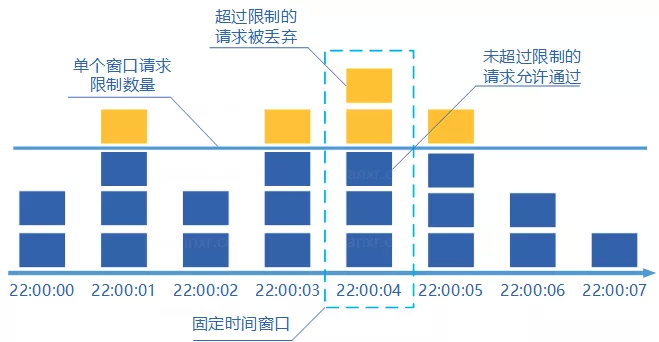
1、固定窗口计数器算法
固定窗口计数器算法概念如下:
将时间划分为多个窗口;
在每个窗口内每有一次请求就将计数器加一;
如果计数器超过了限制数量,则本窗口内所有的请求都被丢弃当时间到达下一个窗口时,计数器重置。
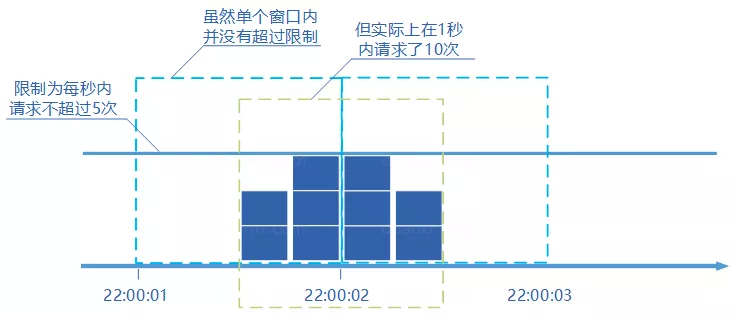
固定窗口计数器是最为简单的算法,但这个算法有时会让通过请求量允许为限制的两倍。考虑如下情况:限制 1 秒内最多通过 5 个请求,在第一个窗口的最后半秒内通过了 5 个请求,第二个窗口的前半秒内又通过了 5 个请求。这样看来就是在 1 秒内通过了 10 个请求。
代码实现 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 package fixed_window_counterimport ( "sync" "sync/atomic" "time" ratelimit_kit "github.com/ulovecode/ratelimit-kit" ) var ( once sync.Once ) var _ ratelimit_kit.RateLimiter = &fixedWindowCounter{}type fixedWindowCounter struct { snippet time.Duration currentRequests int32 allowRequests int32 } func New (snippet time.Duration, allowRequests int32 ) *fixedWindowCounter return &fixedWindowCounter{snippet: snippet, allowRequests: allowRequests} } func (l *fixedWindowCounter) Take () error once.Do(func () go func () for { select { case <-time.After(l.snippet): atomic.StoreInt32(&l.currentRequests, 0 ) } } }() }) curRequest := atomic.LoadInt32(&l.currentRequests) if curRequest >= l.allowRequests { return ratelimit_kit.ErrExceededLimit } if !atomic.CompareAndSwapInt32(&l.currentRequests, curRequest, curRequest+1 ) { return ratelimit_kit.ErrExceededLimit } return nil }
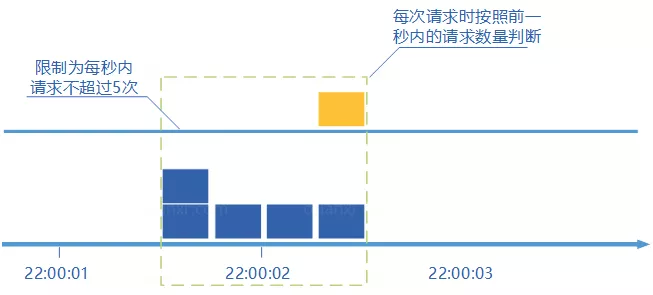
2、滑动窗口计数器算法
滑动窗口计数器算法概念如下:
将时间划分为多个区间;
在每个区间内每有一次请求就将计数器加一维持一个时间窗口,占据多个区间;
每经过一个区间的时间,则抛弃最老的一个区间,并纳入最新的一个区间;
如果当前窗口内区间的请求计数总和超过了限制数量,则本窗口内所有的请求都被丢弃。
滑动窗口计数器是通过将窗口再细分,并且按照时间 “ 滑动 “,这种算法避免了固定窗口计数器带来的双倍突发请求,但时间区间的精度越高,算法所需的空间容量就越大。
代码实现 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 package sliding_window_counterimport ( "sync" "sync/atomic" "time" ratelimit_kit "github.com/ulovecode/ratelimit-kit" ) var ( once sync.Once ) var _ ratelimit_kit.RateLimiter = &slidingWindowCounter{}type slidingWindowCounter struct { incurRequests int32 durationRequests chan int32 accuracy time.Duration snippet time.Duration currentRequests int32 allowRequests int32 } func New (accuracy time.Duration, snippet time.Duration, allowRequests int32 ) *slidingWindowCounter return &slidingWindowCounter{durationRequests: make (chan int32 , snippet/accuracy/1000 ), accuracy: accuracy, snippet: snippet, allowRequests: allowRequests} } func (l *slidingWindowCounter) Take () error once.Do(func () go sliding(l) go calculate(l) }) curRequest := atomic.LoadInt32(&l.currentRequests) if curRequest >= l.allowRequests { return ratelimit_kit.ErrExceededLimit } if !atomic.CompareAndSwapInt32(&l.currentRequests, curRequest, curRequest+1 ) { return ratelimit_kit.ErrExceededLimit } atomic.AddInt32(&l.incurRequests, 1 ) return nil } func sliding (l *slidingWindowCounter) for { select { case <-time.After(l.accuracy): t := atomic.SwapInt32(&l.incurRequests, 0 ) l.durationRequests <- t } } } func calculate (l *slidingWindowCounter) for { <-time.After(l.accuracy) if len (l.durationRequests) == cap (l.durationRequests) { break } } for { <-time.After(l.accuracy) t := <-l.durationRequests if t != 0 { atomic.AddInt32(&l.currentRequests, -t) } } }
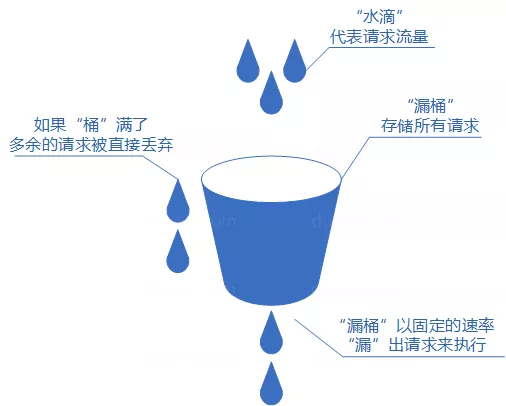
3、漏桶算法
漏桶算法概念如下:
将每个请求视作 “ 水滴 “ 放入 “ 漏桶 “ 进行存储;
“漏桶 “ 以固定速率向外 “ 漏 “ 出请求来执行如果 “ 漏桶 “ 空了则停止 “ 漏水”;
如果 “ 漏桶 “ 满了则多余的 “ 水滴 “ 会被直接丢弃。
漏桶算法多使用队列实现,服务的请求会存到队列中,服务的提供方则按照固定的速率从队列中取出请求并执行,过多的请求则放在队列中排队或直接拒绝。
漏桶算法的缺陷也很明显,当短时间内有大量的突发请求时,即便此时服务器没有任何负载,每个请求也都得在队列中等待一段时间才能被响应。
代码实现 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 package leaky_barrelimport ( "sync" "time" ratelimit_kit "github.com/ulovecode/ratelimit-kit" ) var ( once sync.Once ) var _ ratelimit_kit.RateLimiter = &leakyBarrel{}type leakyBarrel struct { snippet time.Duration allowRequests int32 barrelSize chan struct {} } func New (snippet time.Duration, barrelSize int , allowRequests int32 ) *leakyBarrel return &leakyBarrel{snippet: snippet, barrelSize: make (chan struct {}, int (allowRequests)/barrelSize), allowRequests: allowRequests} } func (t *leakyBarrel) Take () error once.Do(func () go func () for { select { case <-time.After(time.Duration(t.snippet.Nanoseconds() / int64 (t.allowRequests))): t.barrelSize <- struct {}{} } } }() }) select { case <-t.barrelSize: return nil default : } return ratelimit_kit.ErrExceededLimit }
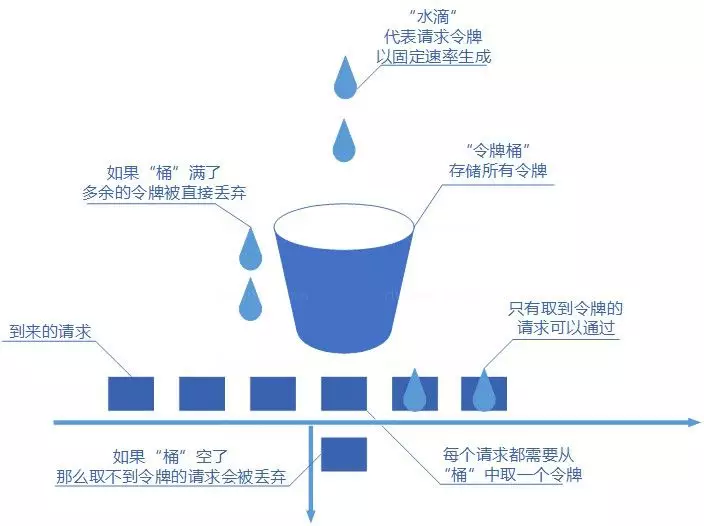
4、令牌桶算法
令牌桶算法概念如下:
令牌以固定速率生成;
生成的令牌放入令牌桶中存放,如果令牌桶满了则多余的令牌会直接丢弃,当请求到达时,会尝试从令牌桶中取令牌,取到了令牌的请求可以执行;
如果桶空了,那么尝试取令牌的请求会被直接丢弃。
令牌桶算法既能够将所有的请求平均分布到时间区间内,又能接受服务器能够承受范围内的突发请求,因此是目前使用较为广泛的一种限流算法。
代码实现 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 package token_bucketimport ( "sync" "time" ratelimit_kit "github.com/ulovecode/ratelimit-kit" ) var ( once sync.Once ) var _ ratelimit_kit.RateLimiter = &tokenBucket{}type tokenBucket struct { snippet time.Duration token chan struct {} allowRequests int32 } func New (snippet time.Duration, allowRequests int32 ) *tokenBucket return &tokenBucket{snippet: snippet, token: make (chan struct {}, allowRequests), allowRequests: allowRequests} } func (t *tokenBucket) Take () error once.Do(func () go func () for { select { case <-time.After(time.Duration(t.snippet.Nanoseconds() / int64 (t.allowRequests))): t.token <- struct {}{} } } }() }) select { case <-t.token: return nil default : } return ratelimit_kit.ErrExceededLimit }
全部代码在github地址如下https://github.com/ulovecode/ratelimit-kit