
在今年的大部分时间里,我一直在 Orbs 团队用 Go 语言做可扩展的区块链的基础设施开发,这是令人兴奋的一年。在 2018 年的时候,我们研究我们的区块链该选择哪种语言实现。因为我们知道 Go 拥有一个良好的社区和一个非常棒的工具集,所以我们选择了 Go。
最近几周,我们进入了系统整合的最后阶段。与任何大型系统一样,可能会在后期阶段出现一些问题,包括性能问题,内存泄漏等。当整合系统时,我们找到了一个不错的方法。在本文中,我将介绍如何调查 Go 中的内存泄漏,详细说明寻找,理解和解决它的步骤。
Golang 提供的工具集非常出色但也有其局限性。首先来看看这个问题,最大的一个问题是查询完整的 core dumps 能力有限。完整的 core dumps 是程序运行时的进程占用内存(或用户内存)的镜像。
我们可以把内存映射想象成一棵树,遍历那棵树我们会得到不同的对象分配和关系。这意味着无论如何
根会持有内存而不被 GCing(垃圾回收)内存的原因。因为在 Go 中没有简单的方法来分析完整的 core dump,所以很难找到一个没有被 GC 过的对象的根。
在撰写本文时,我们无法在网上找到任何可以帮助我们的工具。由于存在 core dump 格式以及从 debug 包中导出该文件的简单方法,这可能是 Google 使用过的一种方法。网上搜索它看起来像是在 Golang pipeline 中创建了这样的 core dump 查看器,但看起来并不像有人在使用它。话虽如此,即使没有这样的解决方案,使用现有工具我们通常也可以找到根本原因。
内存泄漏
内存泄漏或内存压力可以以多种形式出现在整个系统中。通常我们将它们视为 bug,但有时它们的根本原因可能是因为设计的问题。
当我们在新的设计原则下构建我们的系统时,这些考虑并不重要。更重要的是以避免过早优化的方式构建系统,并使你能够在代码成熟后再优化它们,而不是从一开始就过度设计它。然而,一些常见内存压力的问题是:
- 内存分配太多,数据表示不正确
- 大量使用反射或字符串
- 使用全局变量
- 孤儿,没有结束的 goroutines
在 Go 中,创建内存泄漏的最简单方法是定义全局变量,数组,然后将该数据添加到数组。这篇博客文章以一种不错的方式描述了这个例子。
我为什么要写这篇文章呢?当我研究这个例子时,我发现了很多关于内存泄漏的方法。但是,相比较这个例子,我们的真实系统有超过 50 行代码和单个结构。在这种情况下,找到内存问题的来源比该示例描述的要复杂得多。
Golang 为我们提供了一个神奇的工具叫pprof。掌握此工具后,可以帮助调查并发现最有可能的内存问题。它的另一个用途是查找 CPU 问题,但我不会在这篇文章中介绍任何与 CPU 有关的内容。
go tool pprof
把这个工具的方方面面讲清楚需要不止一篇博客文章。我将花一点时间找出怎么使用这个工具去获取有用的东西。在这篇文章里,将集中在它的内存相关功能上。
pprof包创建一个 heap dump 文件,你可以在随后进行分析/可视化以下两种内存映射:
- 当前的内存分配
- 总(累积)内存分配
该工具可以比较快照。例如,可以让你比较显示现在和 30 秒前的差异。对于压力场景,这可以帮助你定位到代码中有问题的区域。
pprof 画像
pprof 的工作方式是使用画像。
画像是一组显示导致特定事件实例的调用顺序堆栈的追踪,例如内存分配。
文件runtime/pprof/pprof.go包含画像的详细信息和实现。
Go 有几个内置的画像供我们在常见情况下使用:
- goroutine - 所有当前 goroutines 的堆栈跟踪
- heap - 活动对象的内存分配的样本
- allocs - 过去所有内存分配的样本
- threadcreate - 导致创建新 OS 线程的堆栈跟踪
- block - 导致阻塞同步原语的堆栈跟踪
- mutex - 争用互斥锁持有者的堆栈跟踪
在查看内存问题时,我们将专注于堆画像。 allocs 画像和它在关于数据收集方面是相同的。两者之间的区别在于 pprof 工具在启动时读取的方式不一样。 allocs 画像将以显示自程序启动以来分配的总字节数(包括垃圾收集的字节)的模式启动 pprof。在尝试提高代码效率时,我们通常会使用该模式。
堆
简而言之,这是 OS(操作系统)存储我们代码中对象占用内存的地方。这块内存随后会被“垃圾回收”,或者在非垃圾回收语言中手动释放。
堆不是唯一发生内存分配的地方,一些内存也在栈中分配。栈主要是短周期的内存。在 Go 中,栈通常用于在函数闭包内发生的赋值。 Go 使用栈的另一个地方是编译器“知道”在运行时需要多少内存(例如固定大小的数组)。有一种方法可以使 Go 编译器将栈“转义”到堆中输出分析,但我不会在这篇文章中谈到它。
堆数据需要“释放”和垃圾回收,而栈数据则不需要。这意味着使用栈效率更高。
这是分配不同位置的内存的简要说明。还有更多内容,但这不在本文的讨论范围之内。
使用 pprof 获取堆数据
获取数据主要有两种方式。第一种通常是把代码加入到测试或分支中,包括导入runtime/pprof,然后调用pprof.WriteHeapProfile(some_file)来写入堆信息。
请注意,WriteHeapProfile是用于运行的语法糖:
1 | // lookup takes a profile name |
根据文档,WriteHeapProfile可以向后兼容。其余类型的画像没有这样的便捷方式,必须使用Lookup()函数来获取其画像数据。
第二个更有意思,是通过 HTTP(基于 Web 的 endpoints)来启用。这允许你从正在运行的 e2e/test 环境中的容器中去提取数据,甚至从“生产”环境中提取数据。这是 Go 运行时和工具集所擅长的部分。整个包文档可以在这里找到,太长不看版,只需要你将它添加到代码中:
1 | import ( |
导入net/http/pprof的“副作用”是在/debug/pprof的 web 服务器根目录下会注册 pprof endpoint。现在使用 curl 我们可以获取要查看的堆信息文件:
1 | curl -sK -v http://localhost:8080/debug/pprof/heap > heap.out |
只有在你的程序之前没有 http listener 时才需要添加上面的http.ListenAndServe()。如果有的话就没有必要再监听了,它会自动处理。还可以使用ServeMux.HandleFunc()来设置它,这对于更复杂的 http 程序有意义。
使用 pprof
所以我们收集了这些数据,现在该干什么呢?如上所述,pprof 有两种主要的内存分析策略。一个是查看当前的内存分配(字节或对象计数),称为inuse。另一个是查看整个程序运行时的所有分配的字节或对象计数,称为alloc。这意味着无论它是否被垃圾回收,都会是所有样本的总和。
在这里我们需要重申一下堆画像文件是内存分配的样例。幕后的pprof使用runtime.MemProfile函数,该函数默认按分配字节每 512KB 收集分配信息。可以修改 MemProfile 以收集所有对象的信息。需要注意的是,这很可能会降低应用程序的运行速度。
这意味着默认情况下,对于在 pprof 监控下抖动的小对象,可能会出现问题。对于大型代码库/长期运行的程序,这不是问题。
一旦收集好画像文件后,就可以将其加载到 pprof 的交互式命令行中了,通过运行:
1 | > go tool pprof heap.out |
我们可以观察到显示的信息
1 | Type: inuse_space |
这里要注意的事项是Type:inuse_space。这意味着我们正在查看特定时刻的内存分配数据(当我们捕获该配置文件时)。type 是sample_index的配置值,可能的值为:
- inuse_space - 已分配但尚未释放的内存数量
- inuse_objects - 已分配但尚未释放的对象数量
- alloc_space - 已分配的内存总量(不管是否已释放)
- alloc_objects - 已分配的对象总量(不管是否已释放)
现在在交互命令行中输入top,将输出顶级内存消费者
1 | (pprof) top |
我们可以看到关于Dropped Nodes的一系列数据,这意味着它们被过滤掉了。一个节点或树中的一个“节点”就是一整个对象。丢弃节点有利于我们更快的找到问题,但有时它可能会隐藏内存问题产生的根本原因。我们继续看一个例子。
如果要该画像文件的所有数据,请在运行 pprof 时添加-nodefraction=0选项,或在交互命令行中键入nodefraction=0。
在输出列表中,我们可以看到两个值,flat和cum。
flat表示堆栈中当前层函数的内存cum表示堆栈中直到当前层函数所累积的内存
仅仅这个信息有时可以帮助我们了解是否存在问题。例如,一个函数负责分配了大量内存但没有保留内存的情况。这意味着某些其他对象指向该内存并维护其分配,这说明我们可能存在系统设计的问题或 bug。
top实际上运行了top10。top 命令支持topN格式,其中N是你想要查看的条目数。在上面的情况,如果键入top70将输出所有节点。
可视化
虽然topN提供了一个文本列表,但 pprof 附带了几个非常有用的可视化选项。可以输入png或gif等等(请参阅go tool pprof -help获取完整信息)。
在我们的系统上,默认的可视化输出类似于:
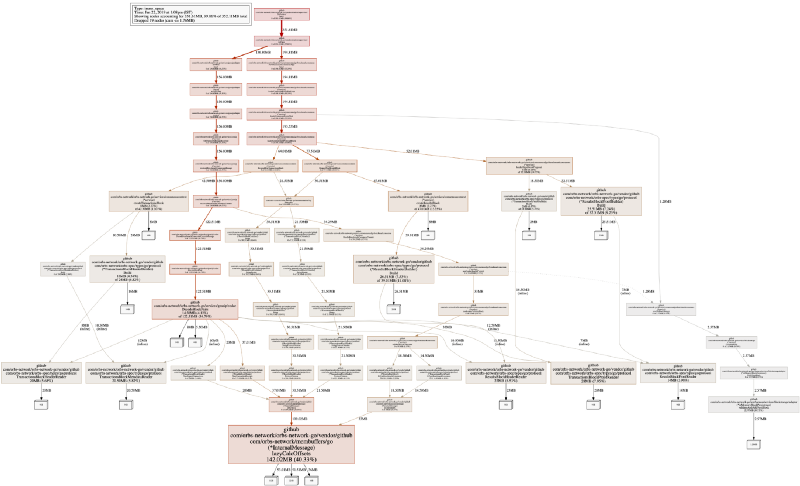
这看起来可能有点吓人,但它是程序中内存分配流程(根据堆栈跟踪)的可视化。阅读图表并不像看起来那么复杂。带有数字的白色方块显示已分配的空间(在图形边缘上是它占用内存的数量),每个更宽的矩形显示调用的函数。
需要注意的是,在上图中,我从执行模式inuse_space中取出了一个 png。很多时候你也应该看看inuse_objects,因为它可以帮助你找到内存分配问题。
深入挖掘,寻找根本原因
到目前为止,我们能够理解应用程序在运行期间内存怎么分配的。这有助于我们了解我们程序的行为(或不好的行为)。
在我们的例子中,我们可以看到内存由membuffers持有,这是我们的数据序列化库。这并不意味着我们在该代码段有内存泄漏,这意味着该函数持有了内存。了解如何阅读图表以及 pprof 输出非常重要。在这个例子中,当我们序列化数据时,意味着我们将内存分配给结构和原始对象(int,string),它不会被释放。
跳到结论部分,我们可以假设序列化路径上的一个节点负责持有内存,例如:
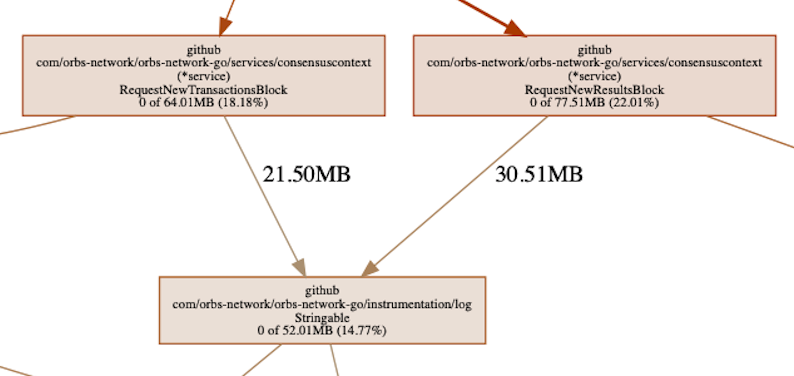
我们可以看到日志库中链中的某个地方,控制着>50MB 的已分配内存。这是由我们的日志记录器调用函数分配的内存。经过思考,这实际上是预料之中的。日志记录器会分配内存,是因为它需要序列化数据以将其输出到日志,因此它会造成进程中的内存分配。
我们还可以看到,在分配路径下,内存仅由序列化持有,而不是任何其他内容。此外,日志记录器保留的内存量约为总量的 30%。综上告诉我们,最有可能的问题不在于日志记录器。如果它是 100%,或接近它,那么我们应该一直找下去 - 但事实并非如此。这可能意味着它记录了一些不应该记录的东西,但不是日志记录器的内存泄漏。
是时候介绍另一个名为list的pprof命令。它接受一个正则表达式,该表达式是内容的过滤器。 “list”实际上是与分配相关的带注释的源代码。在我们可以看到在日志记录器的上下文中将执行list RequestNew,因为我们希望看到对日志记录器的调用。这些调用来自恰好以相同前缀开头的两个函数。
1 | (pprof) list RequestNew |
我们可以看到所做的内存分配位于cum列中,这意味着分配的内存保留在调用栈中。这与图表显示的内容相关。此时很容易看出日志记录器分配内存是因为我们发送了整个“block”对象造成的。这个对象需要序列化它的某些部分(我们的对象是 membuffer 对象,它实现了一些String()函数)。它是一个有用的日志,还是一个好的做法?可能不是,但它不是日志记录器端或调用日志记录器的代码产生了内存泄漏,
list在GOPATH路径下搜索可以找到源代码。如果它搜索的根不匹配(取决于你电脑的项目构建),则可以使用-trim_path选项。这将有助于修复它并让你看到带注释的源代码。当正在捕获堆配置文件时要将 git 设置为可以正确提交。
内存泄漏原因
之所以调查是因为怀疑有内存泄漏的问题。我们发现内存消耗高于系统预期的需要。最重要的是,我们看到它不断增加,这是“这里有问题”的另一个强有力的指标。
此时,在 Java 或.Net 的情况下,我们将打开一些’gc roots’分析或分析器,并获取引用该数据并造成泄漏的实际对象。正如所解释的那样,对于 Go 来说这是不可能的,因为工具问题也是由于 Go 低等级的内存表示。
没有详细说明,我们不知道 Go 把哪个对象存储在哪个地址(指针除外)。这意味着实际上,了解哪个内存地址表示对象(结构)的哪个成员将需要把某种映射输出到堆画像文件。这可能意味着在进行完整的 core dump 之前,还应该采用堆画像文件,以便将地址映射到分配的行和文件,从而映射到内存中表示的对象。
此时,因为我们熟悉我们的系统,所以很容易理解这不再是一个 bug。它(几乎)是设计的。但是让我们继续探索如何从工具(pprof)中获取信息以找到根本原因。
设置nodefraction=0时,我们将看到已分配对象的整个图,包括较小的对象。我们来看看输出:
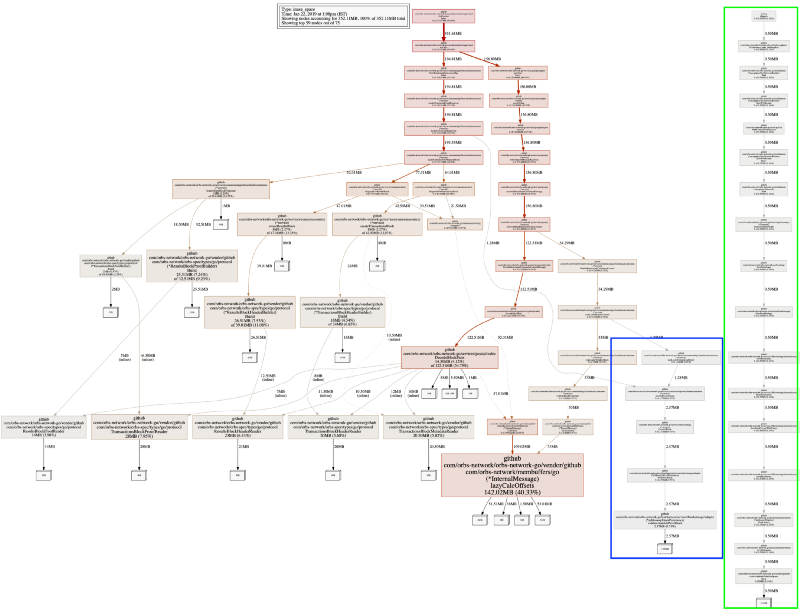
我们有两个新的子树。再次提醒,pprof 堆画像文件是内存分配的采样。对于我们的系统而言 - 我们不会遗漏任何重要信息。这个较长的绿色新子树的部分是与系统的其余部分完全断开的测试运行器,在本篇文章中我没有兴趣考虑它。
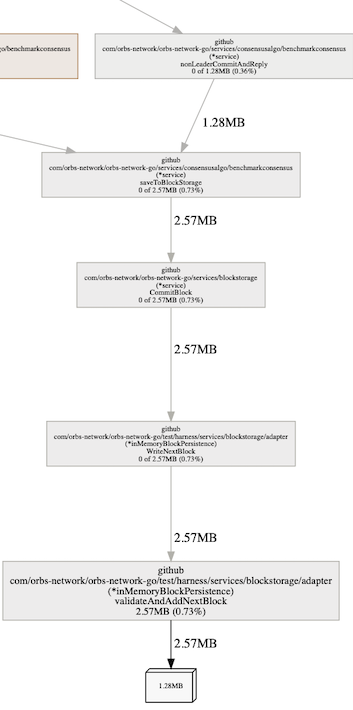
较短的蓝色子树,有一条边连接到整个系统是inMemoryBlockPersistance。这个名字也解释了我们想象的’泄漏’。这是数据后端,它将所有数据存储在内存中而不是持久化到磁盘。值得注意的是,我们可以看到它持有两个大的对象。为什么是两个?因为我们可以看到对象大小为 1.28MB,函数占用大小为 2.57MB。
这个问题很好理解。我们可以使用 delve(调试器)(译者注:deleve)来查看调试我们代码中的内存情况。
如何修复
这是一个糟糕的人为错误。虽然这个过程是有教育意义的,我们能不能做得更好呢?
我们仍然能“嗅探到”这个堆信息。反序列化的数据占用了太多的内存,为什么 142MB 的内存需要大幅减少呢?.. pprof 可以回答这个问题 - 实际上,它确实可以回答这些问题。
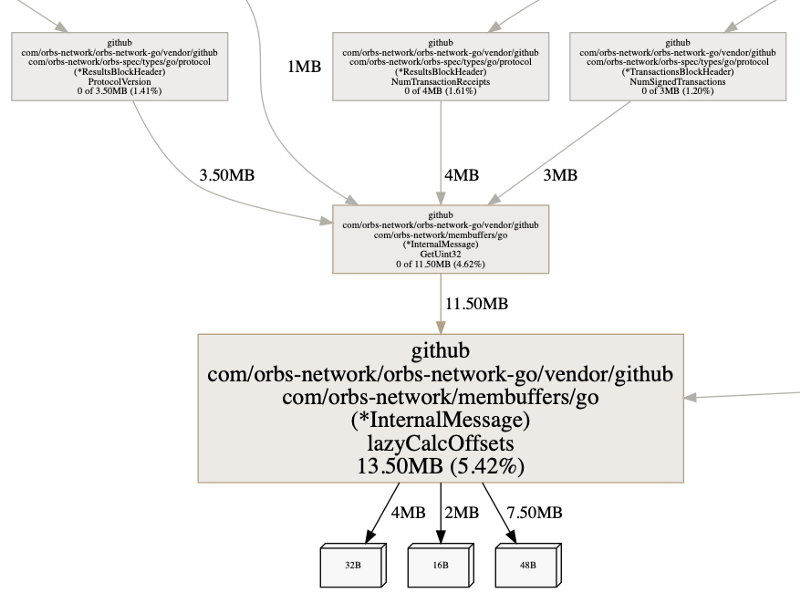
要查看函数的带注释的源代码,我们可以运行list lazy。我们使用lazy,因为我们正在寻找的函数名是lazyCalcOffsets(),而且我们的代码中也没有以 lazy 开头的其他函数。当然输入list lazyCalcOffsets也可以。
1 | (pprof) list lazy |
我们可以看到两个有趣的信息。同样,请记住 pprof 堆画像文件会对有关分配的信息进行采样。我们可以看到flat和cum数字是相同的。这表明分配的内存也在这些分配点被保留。
接下来,我们可以看到make()占用了一些内存。这是很正常的,它是指向数据结构的指针。然而,我们也看到第 43 行的赋值占用了内存,这意味着它分配了内存。
这让我们学习了映射 map,其中 map 的赋值不是简单的变量赋值。本文详细介绍了 map 的工作原理。简而言之,map 与切片相比,map 开销更大,“成本”更大,元素更多。
接下来应该保持警惕:如果内存消费是一个相关的考虑因素的话,当数据不稀疏或者可以转换为顺序索引时,使用map[int]T也没问题,但是通常应该使用切片实现。然而,当扩容一个大的切片时,切片可能会使操作变慢,在 map 中这种变慢可以忽略不计。优化没有万能的方法。
在上面的代码中,在检查了我们如何使用该 map 之后,我们意识到虽然我们想象它是一个稀疏数组,但它并不是那么稀疏。这与上面描述的情况匹配,我们能马上想到一个将 map 改为切片的小型重构实际上是可行的,并且可能使该代码内存效率更好。所以我们将其改为:
1 | func (m *InternalMessage) lazyCalcOffsets() bool { |
就这么简单,我们现在使用切片替代了 map。由于我们接收数据的方式是懒加载进去的,并且我们随后如何访问这些数据,除了这两行和保存该数据的结构之外,不需要修改其他代码。这些修改对内存消耗有什么影响?
让我们来看看benchcmp的几次测试
1 | benchmark old ns/op new ns/op delta |
读取测试的初始化创建分配的数据结构。我们可以看到运行时间提高了约 30%,内存分配下降了 50%,内存消耗提高了> 90%(!)
由于切片(之前是 map)从未添加过很多数据,因此这些数字几乎显示了我们将在生产中看到的内容。它取决于数据熵,但可能在内存分配和内存消耗还有提升的空间。
从同一测试中获取堆画像文件来看一下pprof,我们将看到现在内存消耗实际上下降了约 90%。
需要注意的是,对于较小的数据集,在切片满足的情况就不要使用 map,因为 map 的开销很大。
完整的 core dump
如上所述,这就是我们现在看到工具受限制的地方。当我们调查这个问题时,我们相信自己能够找到根对象,但没有取得多大成功。随着时间的推移,Go 会以很快的速度发展,但在完全转储或内存表示的情况下,这种演变会带来代价。完整的堆转储格式在修改时不向后兼容。这里描述的最新版本和写入完整堆转储,可以使用debug.WriteHeapDump()。
虽然现在我们没有“陷入困境”,因为没有很好的解决方案来探索完全转储(full down)。 目前为止,pprof回答了我们所有的问题。
请注意,互联网会记住许多不再相关的信息。如果你打算尝试自己打开一个完整的转储,那么你应该忽略一些事情,从 go1.11 开始:
- 没有办法在 MacOS 上打开和调试完整的 core dump,只有 Linux 可以。
- https://github.com/randall77/hprof上的工具适用于 Go1.3,它存在 1.7+的分支,但它也不能正常工作(不完整)。
- 在https://github.com/golang/debug/tree/master/cmd/viewcore上查看并不真正编译。它很容易修复(内部的包指向 golang.org 而不是 github.com),但是,在 MacOS 或者 Linux 上可能都不起作用。
- 此外,https://github.com/randall77/corelib在 MacOS 也会失败
pprof UI
关于 pprof,要注意的一个细节是它的 UI 功能。在开始调查与使用 pprof 画像文件相关的问题时可以节省大量时间。(译者注:需要安装 graphviz)
1 | go tool pprof -http=:8080 heap.out |
此时它应该打开 Web 浏览器。如果没有,则浏览你设置的端口。它使你能够比命令行更快地更改选项并获得视觉反馈。消费信息的一种非常有用的方法。
UI 确实让我熟悉了火焰图,它可以非常快速地暴露代码的罪魁祸首。
结论
Go 是一种令人兴奋的语言,拥有非常丰富的工具集,你可以用 pprof 做更多的事情。例如,这篇文章没有涉及到的 CPU 分析。
其他一些好的文章:
- https://rakyll.org/archive/ - 我相信这是围绕性能监控的主要贡献者之一,她的博客上有很多好帖子
- https://github.com/google/gops - 由JBD(运行 rakyll.org)编写,此工具保证是自己的博客文章。
- https://medium.com/@cep21/using-go-1-10-new-trace-features-to-debug-an-integration-test-1dc39e4e812d -
go tool trace是用来做 CPU 分析的,这是一个关于该分析功能的不错的帖子。

