
在大学时期,学习 KMP 算法感觉自己好似懂,但是好似又不懂,书里看的云里雾里不知所起然,最近对算法重新进行学习,对于 KMP 算法有了更深刻的理解。
一、KMP 算法
1.算法由来
KMP 算法是由D.E. Knuth、J.H.Morris和V.R. Pratt提出的,可在一个主文本字符串S内查找一个词W的出现位置。此算法通过运用对这个词在不匹配时本身就包含足够的信息来确定下一个匹配将在哪里开始的发现,从而避免重新检查先前匹配的字符。这个算法是由高德纳和沃恩·普拉特在1974年构思,同年詹姆斯·H·莫里斯也独立地设计出该算法,最终由三人于1977年联合发表。该算法减少了BF算法中i回溯所进行的无谓操作,极大地提高了字符串匹配算法的效率。 [1],由D.E.Knuth,J.H.Morris和V.R.Pratt提出的,因此人们称它为克努特—莫里斯—普拉特操作(简称KMP算法)。
2.算法的核心思想
KMP算法的核心是利用匹配失败后的信息,尽量减少模式串与主串的匹配次数以达到快速匹配的目的。具体实现就是通过一个next()函数实现,函数本身包含了模式串的局部匹配信息。KMP算法的时间复杂度O(m+n)。
3.解释
我们BF算法就是通过逐个扫描,从主串到模版串进行注意匹配,而 kmp 算法做的就是减少从头开始匹配的过程,来避免多次进行不必要的匹配。那么假设我们已经得到了模板串的滑动数组,该数组作用就是当从某一个位置匹配失败时,可以迅速的找到之前一个类似的匹配位置。因此我们可以根据 BF 算法轻易的写出关于kmp算法的雏形。
1 | func kmpMatch(s string, m string) int { |
我可以根据字符串遍历的程度,要判断是否匹配成功,如果模版串遍历完成,遍历索引等于模版字符串的长度,那么就说明在主串中找到了包含模版串。否则就能知道是主串已经遍历完成,但是模版串还没有遍历完成。
在整个for循环中,如果主串的位置,和模板串的字符匹配,那么就进行下一个位置的匹配。如果滑动数组已经滑动到最开始的位置,那么直接将主串向前滑动一步,此时模板串已经处于索引为0处。如果以上两种情况都不是,那么认为滑动数组还没有滑动到索引为0的位置,认为当前位置可以继续尝试匹配,那么让滑动数组回到上一个认为可以滑动的位置,再进行匹配。
下面我门讨论一下如何得到next数组:

图上给出的就是一个next数组,其中当前值代表的是之前有多少个字符串与开头字符串相匹配,可以看到i=0时,没有字符串和它匹配,并且是开头就特殊标记为 -1,i=1时,我们定义滑动数组为前缀数组与后缀数组(不包含第一个字符)的匹配,所以当前i=1位置,如果即使是a,值也为0。所以将当前位置值设置为0。再来看i=2时 ,next[1]为0,那么表示从头开始匹配,s[0](a)位置与s[1](b)位置不匹配,那么之前没有匹配的字符串,所以当前值也填为0。i=3时,这个时候可以看到s[0](a)位置与s[2](a)位置匹配,所以当前位置可以设置为1,反复如此,求出next数组。
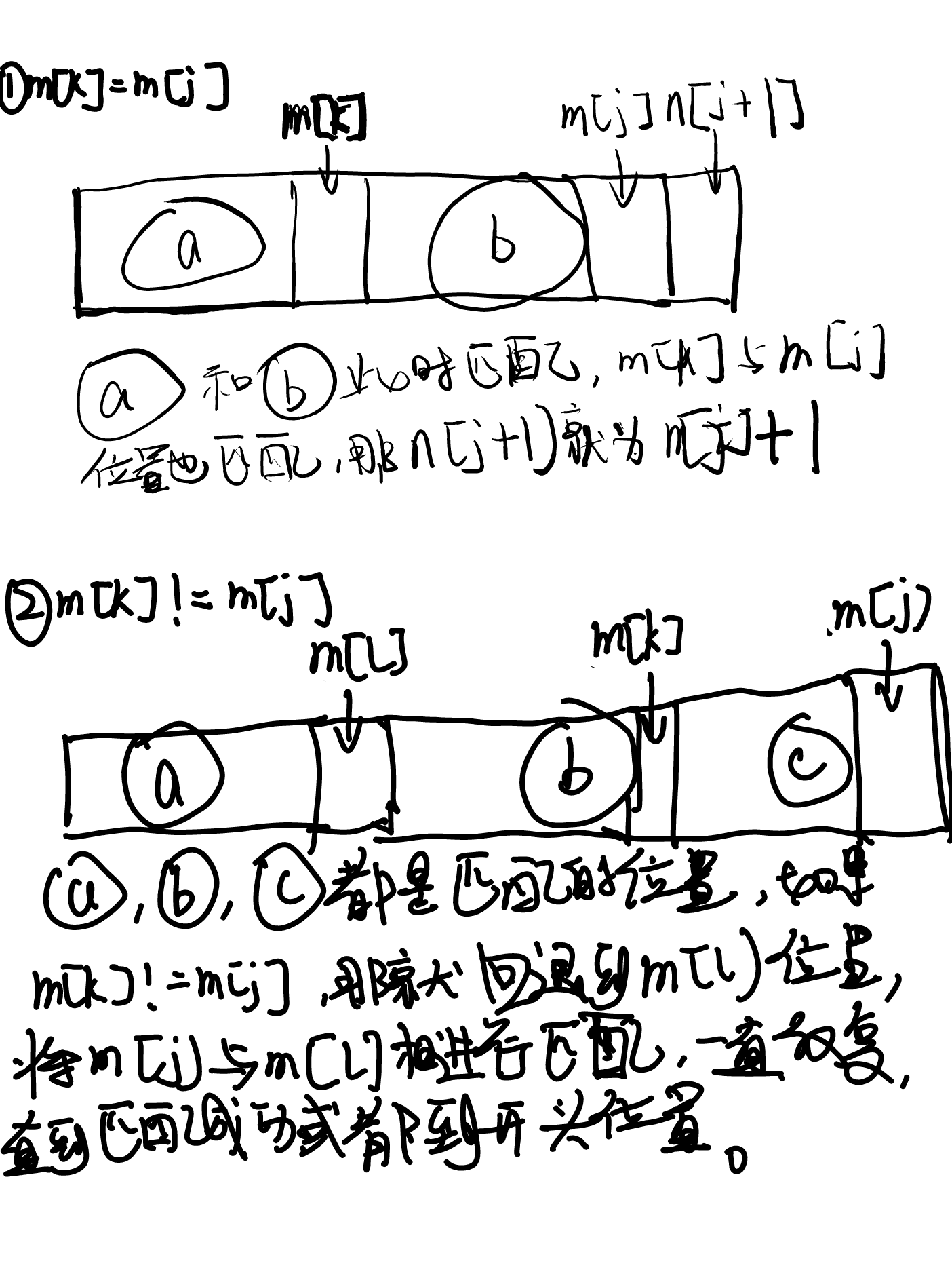
那么上图就画出了匹配情况m[k]与m[j]匹配情况与不匹配的情况。
1 | func getNextArray(m string) []int { |
next[0]规定为-1,只是一个特殊的标记这是滑动数组的开头,并且之前也可能会有相匹配的字符串,一般为负数就可以,通常为-1。m[1]来说,m[0],但next数组的定义要求任何子串的后缀不能包括第一个字符(m[0]),m[1]之前的字符串只有长度为0的后缀字符串,next[1]为0。
创建一个变量cn,作用是记录当前匹配的长度。创建一个遍历pos,作用是推进下标前进,判断当前位置之前有几个字符串于之匹配。这样实际上是两个指针cn指针代表当前匹配的长度,pos指针则是主指针,推动数组下标前进,更新当前匹配了之前有多少个字符串相匹配。
在for循环内,从位置index = 2开始匹配。
- 如果当前位置的前一个位置的字符 和
m[cn]字符相等,那么将当前将记录当前匹配长度的cn++,同时将该pos位置的值设置为当前匹配的长度,然后将pos++,进行下一轮匹配。 - 否则,如果当前记录的匹配长度没有到0,那么将
cn指针的位置回退到前一个位置进行匹配。 - 否则,如果当前
cn指针的位置已经到0,那么就将pos位置的值设置为0,因为之前没有任何一个位置匹配,同时pos++,进行下一轮匹配。

