
这是三部分系列中的第三篇文章,它将提供对Go中调度程序背后的机制和语义的理解。这篇文章重点关注并发性。
介绍
当我解决问题时,特别是如果这是一个新问题,我最初并不会考虑并发是否适合。我首先寻找顺序解决方案并确保它正常工作。然后在可读性和技术评论之后,我将开始提出并发性是否合理和实用的问题。有时很明显,并发性是一个很好的选择,有时则不太清楚。
在本系列的第一部分中,我解释了操作系统调度程序的机制和语义,如果你计划编写多线程代码,我认为这很重要。在第二部分中,我解释了Go调度程序的语义,我认为这对于理解如何在Go中编写并发代码非常重要。在这篇文章中,我将开始将操作系统和Go调度程序的机制和语义结合在一起,以便更深入地了解并发性和不兼容性。
这篇文章的目标是:
提供有关必须考虑的语义的指导,以确定工作负载是否适合使用并发。
向你展示不同类型的工作负载如何改变语义,从而改变你想要做出的工程决策。
什么是并发
并发意味着“乱序”执行。获取一组指令,否则这些指令将按顺序执行,并找到一种无序执行它们的方法,并仍然产生相同的结果。对于你面前的问题,必须明显的是,乱序执行会增加价值。当我说价值时,我的意思是为复杂性成本增加足够的性能增益。根据你的问题,可能无法执行乱序执行甚至有意义。
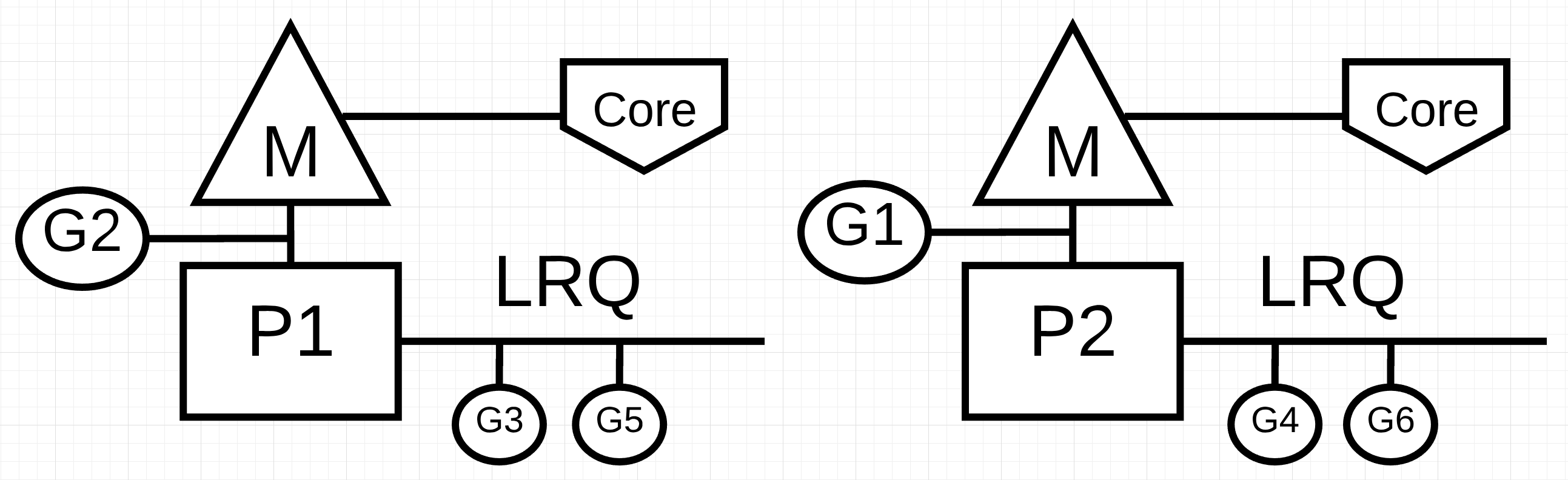
图1:并发与并行
在图1中,你可以看到两个逻辑处理器(P)的图表,每个处理器的独立OS线程(M)连接到计算机上的独立硬件线程(Core)。你可以看到两个Goroutines(G1和G2)并行执行,同时在各自的操作系统上执行它们的指令。在每个逻辑处理器中,三个Goroutines轮流共享各自的OS线程。所有这些Goroutines同时运行,没有特定顺序执行他们的指令并在OS线程上共享时间。
这就是摩擦,有时利用没有并行性的并发性实际上可以减慢吞吐量。有趣的是,有时利用并发性和并行性并不会给你带来比你认为可以实现的更大的性能提升。
工作负载
你怎么知道什么时候可能无序执行或有意义?了解问题所处理的工作负载类型是一个很好的起点。在考虑并发时,有两种类型的工作负载是很重要的。
CPU绑定:这是一个永远不会产生Goroutines自然进出等待状态的工作负载。这是不断进行计算的工作。计算Pi到第N位的线程将是CPU绑定的。
IO绑定:这是一个导致Goroutines自然进入等待状态的工作负载。这项工作包括请求通过网络访问资源,或将系统调用进入操作系统,或等待事件发生。需要读取文件的Goroutine将是IO绑定。我会包含同步事件(互斥,原子),导致Goroutine等待此类别的一部分。
使用CPU绑定工作负载,你需要并行来利用并发性。处理多个Goroutines的单个操作系统效率不高,因为Goroutines作为其工作负载的一部分不会进入和退出等待状态。拥有更多的Goroutines而不是操作系统/硬件线程可以减慢工作负载执行速度,因为在操作系统线程上移动和关闭Goroutines的延迟成本(花费的时间)。上下文切换正在为你的工作负载创建“Stop The World”事件,因为在切换期间你的工作负载都没有被执行。
使用IO绑定工作负载,你不需要并行来使用并发。单个操作系统线程可以高效地处理多个Goroutines,因为Goroutines作为其工作负载的一部分自然地进出等待状态。拥有比操作系统/硬件线程更多的Goroutines可以加快工作负载执行速度,因为在操作系统线程上移动和移除Goroutines的延迟成本并不会产生“停止世界”事件。你的工作负载自然停止,这允许不同的Goroutine有效地利用相同的操作系统线程,而不是让操作系统线程闲置。
你如何知道每个线程有多少Goroutines提供最佳吞吐量?很少有Goroutines,你有更多的空闲时间。Goroutines太多,你有更多的上下文切换延迟时间。这是你要考虑的事情,但超出了这个特定职位的范围。
现在,重要的是要检查一些代码以巩固你识别工作负载何时可以利用并发性的能力,何时不能并且是否需要并行性。
添加数字
我们不需要复杂的代码来可视化和理解这些语义。查看以下命名的函数,该函数add汇总整数集合。
清单1
https://play.golang.org/p/r9LdqUsEzEz
1 | 36 func add(numbers []int) int { |
在第36行的清单1中,add声明了一个名为的函数,它接受一个整数集合并返回集合的总和。它从第37行开始,v变量声明包含总和。然后在第38行,函数线性地遍历集合,并且每个数字被添加到第39行的当前总和。最后在第41行,函数将最终的总和返回给调用者。
问题:该add功能是一个适合乱序执行的工作负载吗?我相信答案是肯定的。整数集合可以分解为较小的列表,并且可以同时处理这些列表。一旦将所有较小的列表相加,就可以将这组和被加在一起以产生与顺序版本相同的答案。
但是,还有另一个问题浮现在脑海中。应该独立创建和处理多少个较小的列表以获得最佳吞吐量?要回答此问题,你必须知道add正在执行的工作负载类型。该add函数正在执行CPU绑定工作负载,因为该算法正在执行纯数学,并且它不会导致goroutine进入自然等待状态。这意味着每个操作系统线程使用一个Goroutine就可以获得良好的吞吐量。
下面的清单2是我的并发版本add。
注意:编写并发版本的add时,可以采用多种方法和选项。暂时不要挂断我的特定实现。如果你有一个更易读的版本,表现相同或更好,我希望你能分享它。
清单2
https://play.golang.org/p/r9LdqUsEzEz
1 | 44 func addConcurrent(goroutines int, numbers []int) int { |
在清单2中,显示了addConcurrent函数,它是函数的并发版本add。并发版本使用26行代码而不是非并发版本的5行代码。有很多代码,所以我只强调要理解的重要内容。
第48行:每个Goroutine都会得到他们自己独特但更小的数字列表。列表的大小是通过获取集合的大小并将其除以Goroutines的数量来计算的。
第53行:创建Goroutines池以执行添加工作。
第57-59行:最后一个Goroutine将添加剩余的数字列表,这些数字可能比其他Goroutines更大。
第66行:将较小的列表的总和加在一起作为最终总和。
并发版本肯定比顺序版本更复杂但复杂性值得吗?回答这个问题的最好方法是创建一个基准。对于这些基准测试,我使用了1000万个数字的集合,关闭了垃圾收集器。有一个使用该add函数的顺序版本和使用该函数的并发版本addConcurrent。
清单3
1 | func BenchmarkSequential(b *testing.B) { |
清单3显示了基准函数。以下是所有Goroutines只有一个操作系统线程可用的结果。顺序版本使用1个Goroutine,并发版本runtime.NumCPU在我的机器上使用或8个Goroutines。在这种情况下,并发版本正在利用没有并行性的并发性。
清单4
1 | 10 Million Numbers using 8 goroutines with 1 core |
注意:在本地计算机上运行基准测试很复杂。有许多因素可能导致你的基准测试不准确。确保你的机器尽可能空闲并运行基准测试几次。你希望确保在结果中看到一致性。通过测试工具运行两次基准测试,可以为此基准测试提供最一致的结果。
清单4中的基准测试表明,当只有一个操作系统线程可供所有Goroutines使用时,Sequential版本比Concurrent快约10%到13%。这是我所期望的,因为并发版本具有单个操作系统线程上的上下文切换和Goroutines管理的开销。
以下是每个Goroutine可用的单独操作系统线程的结果。顺序版本使用1个Goroutine,并发版本runtime.NumCPU在我的机器上使用或8个Goroutines。在这种情况下,并发版本正在利用并行性和并发性。
清单5
1 | 10 Million Numbers using 8 goroutines with 8 cores |
清单5中的基准测试表明,当每个Goroutine可以使用单独的操作系统线程时,并发版本比顺序版本快大约41%到43%。这是我所期望的,因为所有Goroutines现在并行运行,八个Goroutines同时执行他们的同时工作。
排序
重要的是要了解并非所有CPU绑定工作负载都适合并发。当破坏工作和/或组合所有结果非常昂贵时,这是主要的。使用名为冒号排序的排序算法可以看到这方面的一个例子。查看以下在Go中实现冒泡排序的代码。
清单6
https://play.golang.org/p/S0Us1wYBqG6
1 | 01 package main |
在清单6中,有一个用Go编写的冒泡排序的例子。这种排序算法会扫描每次传递时交换值的整数集合。根据列表的顺序,在对所有内容进行排序之前,可能需要多次遍历集合。
问题:该bubbleSort功能是一个适合乱序执行的工作负载吗?我相信答案是否定的。整数集合可以分解为较小的列表,并且可以同时对这些列表进行排序。但是,在完成所有并发工作之后,没有有效的方法将较小的列表排序在一起。以下是冒泡排序的并发版本的示例。
清单8
1 | 01 func bubbleSortConcurrent(goroutines int, numbers []int) { |
在清单8中,显示了bubbleSortConcurrent函数,它是函数的并发版本冒泡排序。它使用多个Goroutines同时对列表的某些部分进行排序。但是,你剩下的是以块为单位的已排序值列表。给定一个包含12个数字的36个数字的列表,如果整个列表在第25行没有再次排序,这将是结果列表。
清单9
1 | Before: |
由于冒泡排序的本质是扫描列表,因此bubbleSort对第25行的调用将抵消使用并发性带来的任何潜在收益。使用冒泡排序,使用并发性没有性能提升。
阅读文件
已经介绍了两个CPU绑定工作负载,但是IO绑定工作负载呢?当Goroutines自然地进出等待状态时,语义是否不同?查看读取文件并执行文本搜索的IO绑定工作负载。
第一个版本是一个名为的函数的顺序版本find。
清单10
https://play.golang.org/p/8gFe5F8zweN
1 | 42 func find(topic string, docs []string) int { |
在清单10中,你可以看到该find函数的顺序版本。在第43行,found声明一个名为变量的变量,以维持topic在给定文档中找到指定的次数。然后在第44行,迭代文档并使用该read函数在第45行读取每个文档。最后在第49-53行,包中的Contains函数strings用于检查是否可以在从文档中读取的项集合中找到主题。如果找到主题,则found变量加1。
这是read被调用的函数的实现find。
清单11
https://play.golang.org/p/8gFe5F8zweN
1 | 33 func read(doc string) ([]item, error) { |
read清单11中的函数time.Sleep以一毫秒的调用开始。此调用用于模拟在我们执行实际系统调用以从磁盘读取文档时可能产生的延迟。此延迟的一致性对于准确测量find针对并发版本的顺序版本的性能非常重要。然后在第35-39行,将存储在全局变量中的模拟xml文档file解组为struct值以进行处理。最后,在第39行将一组项目返回给调用者。
有了顺序版本,这里是并发版本。
注意:编写并发版本的find时,可以采用多种方法和选项。暂时不要挂断我的特定实现。如果你有一个更易读的版本,表现相同或更好,我希望你能分享它。
清单12
https://play.golang.org/p/8gFe5F8zweN
1 | 58 func findConcurrent(goroutines int, topic string, docs []string) int { |
在清单12中,显示了findConcurrent函数,它是函数的并发版本find。并发版本使用30行代码而不是非并发版本的13行代码。我实现并发版本的目标是控制用于处理未知数量文档的Goroutine的数量。我选择使用通道用于给予Goroutines池的池模式。
有很多代码,所以我只强调要理解的重要内容。
第61-64行:创建一个通道并填充要处理的所有文档。
第65行:通道关闭,因此当处理完所有文件后,Goroutines池自然终止。
第70行:创建了Goroutines游泳池。
第73-83行:池中的每个Goroutine从通道接收文档,将文档读入内存并检查主题的内容。当匹配时,本地找到的变量递增。
第84行:将各个Goroutine计数的总和加在一起作为最终计数。
并发版本肯定比顺序版本更复杂但复杂性值得吗?再次回答这个问题的最好方法是创建一个基准。对于这些基准测试,我使用了一千个文件的集合,关闭了垃圾收集器。有一个使用该find函数的顺序版本和使用该函数的并发版本findConcurrent。
清单13
1 | func BenchmarkSequential(b *testing.B) { |
清单13显示了基准函数。以下是所有Goroutines只有一个操作系统线程可用的结果。顺序使用1个Goroutine,并发版本runtime.NumCPU在我的机器上使用或8个Goroutines。在这种情况下,并发版本正在利用没有并行性的并发性。
清单14
1 | 10 Thousand Documents using 8 goroutines with 1 core |
清单14中的基准测试显示,当只有一个操作系统线程可用于所有Goroutines时,并发版本比顺序版本快大约87%到88%。这是我所期望的,因为所有Goroutines都有效地共享单个操作系统线程。read调用时每个Goroutine发生的自然上下文切换允许在单个操作系统线程上进行更多工作。
以下是并行使用并发时的基准。
清单15
1 | 10 Thousand Documents using 8 goroutines with 1 core |
清单15中的基准测试表明,引入额外的操作系统线程不能提供更好的性能。
结论
这篇文章的目的是提供有关必须考虑的语义的指导,以确定工作负载是否适合使用并发。我尝试提供不同类型的算法和工作负载的示例,以便你可以看到语义上的差异以及需要考虑的不同工程决策。
你可以清楚地看到,使用IO绑定工作负载并不需要并行性来获得性能上的大幅提升。这与你在CPU绑定工作中看到的相反。当涉及像冒泡排序这样的算法时,并发性的使用会增加复杂性,而不会带来任何实际的性能优势。确定你的工作负载是否适合并发,然后确定必须使用正确语义的工作负载类型非常重要。
原文:
1) Scheduling In Go : Part I - OS Scheduler
2) Scheduling In Go : Part II - Go Scheduler
3) Scheduling In Go : Part III - Concurrency

